
Cache concepts like mapping techniques and coherency are a good way to check one’s understanding of digital architecture. Due to this very reason, it is quite common to get asked these questions in an interview.
In this article, I will try to explain the cache mapping techniques using their hardware implementation. This will help you visualize the difference between different mapping techniques, using which you can take informed decisions on which technique to use given your requirements. You will be able to answer questions like which technique requires the most hardware, which technique is the fastest, how the hardware changes when associativity changes, etc.
I assume the reader has a basic understanding of the mapping techniques as I am not going to go deep into that, there are a lot of very good articles covering this topic. This article only focuses on the hardware implementation of those techniques.
Direct Mapping
In this technique, each address in main memory maps to a unique cache location. See the picture below:

We can see that the cache address 0 can only have data from any one of the 4 main memory locations, viz. 0, 4, 8 or 12. If we write these values in hexadecimal, we get:
0 – 0000
4 – 0100
8 – 1000
12 – 1100
We notice the two LSBs are same for all the locations and these will be used to index in to the cache memory, and are hence called “index bits”. Now that we have identified the memory location in the cache where our required data might be present, the next challenge is to confirm if the required data is present in that cache memory location or not. To do that we use the upper two bits of the addresses, which are called “tag bits”. We compare the tag value stored in cache to the tag bits from main memory, and if they match, we know the data we are looking for is present in cache.
A location in cache memory can also be divided to hold data from different main memory locations. In that case, to retrieve the data we will need “offset bits”. It is depicted in the picture below:

There is also a “valid bit” associated with all the cache memory locations to indicate whether the data in a particular location is valid or not.
See the hardware implementation below for more clear understanding:

As we can see here, there is only one comparison happening because we know if the required data is not there, it will not be anywhere else in the cache. Hence, less hardware is required for this mapping technique.
Fully Associative Mapping
This permits data to be stored in any cache block instead of forcing each memory address into one particular block. There is no index field in address anymore, the entire address must be used as the tag, increasing the total cache size. Data can literally be anywhere in the cache memory, so we must check the tag of each cache block resulting in a lot of comparators.
As you would expect, this is very costly in terms of hardware. Let us see its implementation:

This mapping needs comparison with all the tag bits. The cache controller must compare every block’s tag until the data is not found. This means that if the required data is not present in cache, we would only get to know this after cycling through all the tag bits in the cache memory. Due to this reason, the fully associative mapping takes more time to search the data.
Set Associative Cache
This technique gives us the best of both worlds. The cache memory is divided into a group of blocks called sets. Each main memory address maps to exactly one set in the cache (like direct mapping), but data may be placed in any block within that set (like fully associative mapping).
If a set has k lines, the mapping is called a k-way set associative cache. 1-way set associative cache is basically a direct-mapped cache. Similarly, if a cache has 2^k blocks, a 2^k-way set associative cache would be the same as a fully associative cache.

Let us assume each block has 16 bits. To address all 16 bits, we will need 4 offset bits. For a 1-way cache, the next 3 bits will be the set index bits. For a 2-way cache, the next 2 bits will be the set index bits. For a 4-way cache, the next 1 bit will be the set index bit. Let us see this in the hardware implementation of a 2-way set associative cache.
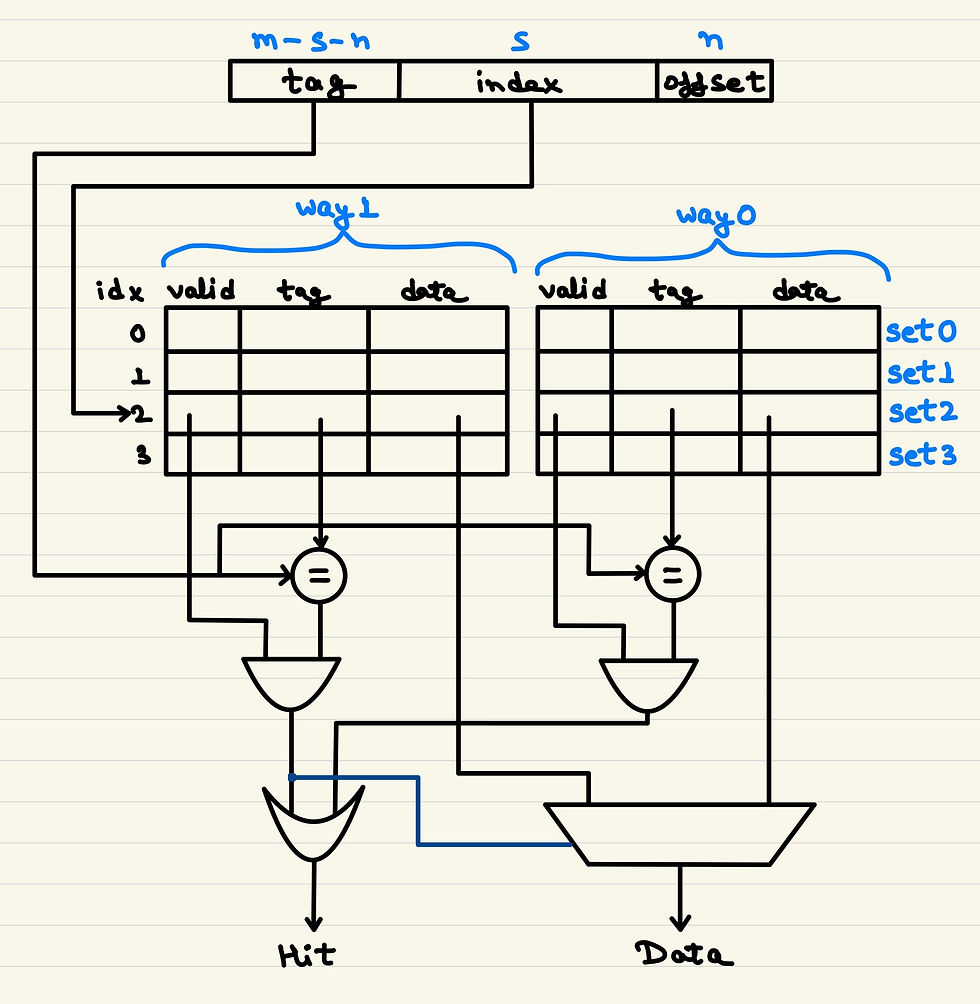
We can see that the number of comparisons required depends on the number of ways. For a 2-way set associative cache as shown in above figure, we will need only two comparisons. Also, the tags will be a little shorter for a set associative cache when compared to a fully associative cache.
Few observations that can be made looking at the hardware implementations of cache mapping techniques:
In a cache with 3 sets, only one-third of the cache needs to be searched. In a cache with 4 sets, only one-fourth of the cache needs to be searched.
Each increase in the level of associativity also increases the number of tags that must be checked in order to locate a specific block, which also means an increase in cache latency.
With a 2-way cache, the number of potential collisions is reduced compared to the direct mapped scheme.
Though a 2-way cache latency is less than a 4-way cache, its number of potential collisions is higher.
These are only some of points that we can make out from the hardware implementations. We can answer a lot of questions if we fully understand what’s in this article. Here’s an interview question for you to try: Going from a 2-way to a 4-way associativity, how would it affect the timing, power and area, and which types of misses would it reduce?
That is all for this article. Let me know if you feel I missed something. Use the Contact page to drop me a mail.
See you in the next one!
Comments